XGBoost 作为构建分类模型比较出色的算法,是在GBDT之后又做提升的,我这里通过自己正在做的项目进行一个基于XGBoost的调参实践。以下为具体步骤:
1. 常用参数解读
- estimator:所使用的分类器,如果比赛中使用的是XGBoost的话,就是生成的model。比如: model = xgb.XGBRegressor(**other_params)
- param_grid:值为字典或者列表,即需要最优化的参数的取值。比如:cv_params = {‘n_estimators’: [550, 575, 600, 650, 675]}
- scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring=’roc_auc’,根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。scoring参数选择如下
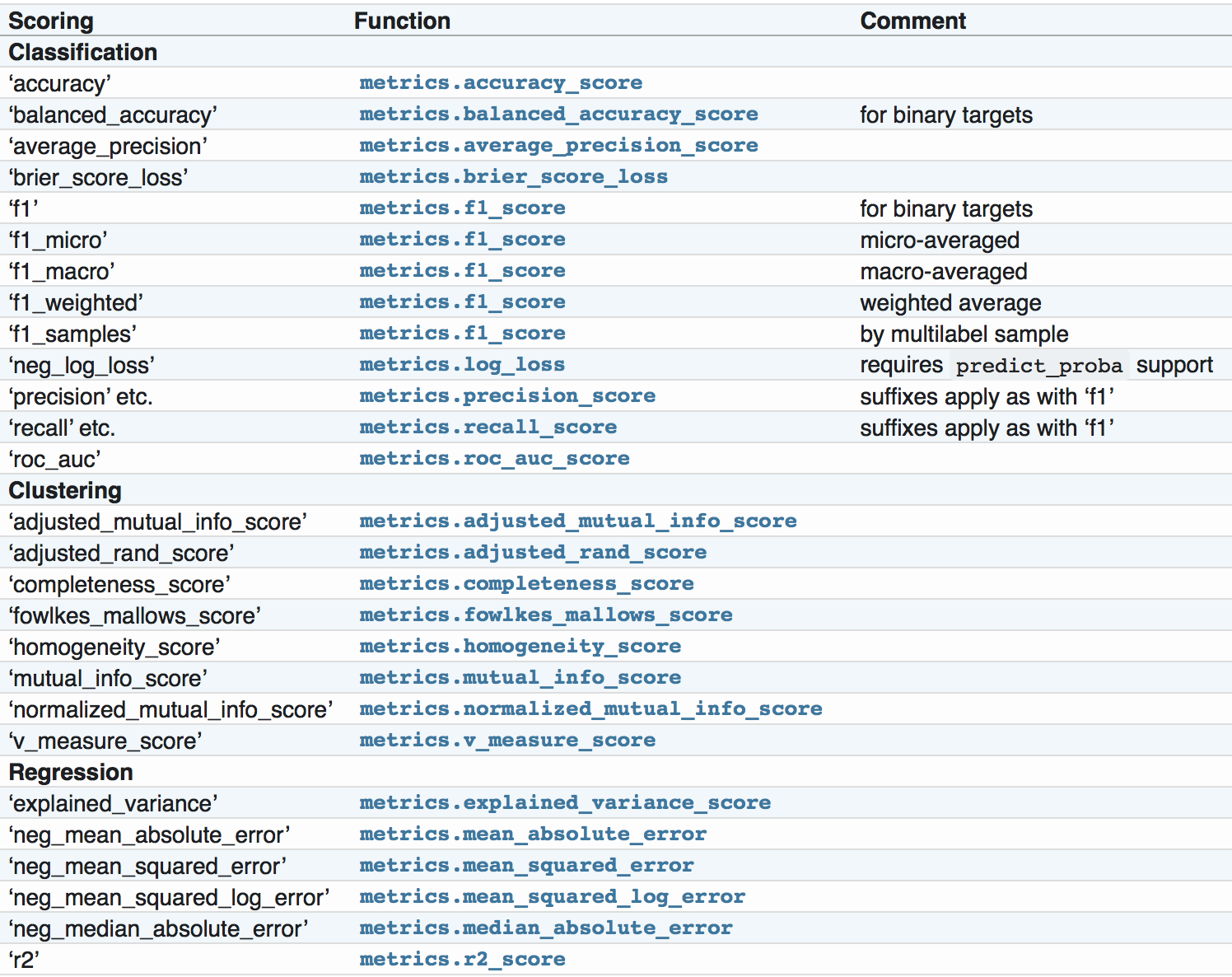
https://scikit-learn.org/stable/modules/model_evaluation.html
调参开始一般要初始化一些值:
- learning_rate: 0.1
- n_estimators: 500
- max_depth: 5
- min_child_weight: 1
- subsample: 0.8
- colsample_bytree:0.8
- gamma: 0
- reg_alpha: 0
- reg_lambda: 1
2. 调参过程
调参的时候一般按照以下顺序来进行:
1. 最佳迭代次数:n_estimators
1 | if __name__ == '__main__': |
我这里的结果如下:
1 | 每轮迭代运行结果:[mean: 0.64585, std: 0.00735, params: {'n_estimators': 400}, mean: 0.64577, std: 0.00760, params: {'n_estimators': 500}, mean: 0.64517, std: 0.00750, params: {'n_estimators': 600}, mean: 0.64444, std: 0.00775, params: {'n_estimators': 700}, mean: 0.64368, std: 0.00766, params: {'n_estimators': 800}] |
所以选取以下参数继续:
1 | cv_params = {'n_estimators': [350, 375, 400, 425, 450]} |
结果:
1 | 每轮迭代运行结果:[mean: 0.64750, std: 0.00506, params: {'n_estimators': 350}, mean: 0.64760, std: 0.00506, params: {'n_estimators': 375}, mean: 0.64786, std: 0.00505, params: {'n_estimators': 400}, mean: 0.64805, std: 0.00479, params: {'n_estimators': 425}, mean: 0.64813, std: 0.00471, params: {'n_estimators': 450}] |
所以继续:
1 | cv_params = {'n_estimators': [450, 460, 470, 480, 490]} |
(也可以粒度不用这么细,看心情,当然粒度越细越准确)
结果:
1 | 每轮迭代运行结果:[mean: 0.64785, std: 0.00566, params: {'n_estimators': 450}, mean: 0.64791, std: 0.00572, params: {'n_estimators': 460}, mean: 0.64783, std: 0.00568, params: {'n_estimators': 470}, mean: 0.64785, std: 0.00570, params: {'n_estimators': 480}, mean: 0.64798, std: 0.00578, params: {'n_estimators': 490}] |
所以选取 n_estimators: 490
2. 更新参数后,开始调试min_child_weight以及max_depth
1 | cv_params = {'max_depth': [3, 4, 5, 6, 7, 8, 9, 10], 'min_child_weight': [1, 2, 3, 4, 5, 6]} |
结果:
1 | Fitting 5 folds for each of 48 candidates, totalling 240 fits |
3. 接下来调gamma
1 | cv_params = {'gamma': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]} |
结果:
1 | Fitting 5 folds for each of 6 candidates, totalling 30 fits |
4. 接下来是 subsample 和 colsample_bytree
1 | cv_params = {'subsample': [0.6, 0.7, 0.8, 0.9], 'colsample_bytree': [0.6, 0.7, 0.8, 0.9]} |
结果:
1 | Fitting 5 folds for each of 16 candidates, totalling 80 fits |
5. 接下来是 reg_alpha 和 reg_lambda
1 | cv_params = {'reg_alpha': [0.05, 0.1, 1, 2, 3], 'reg_lambda': [0.05, 0.1, 1, 2, 3]} |
结果如下:
1 | Fitting 5 folds for each of 25 candidates, totalling 125 fits |
6. 最后是 learning_rate
一般要调小学习率来测试
1 | cv_params = {'learning_rate': [0.01, 0.05, 0.07, 0.1, 0.2]} |
结果:
1 | Fitting 5 folds for each of 5 candidates, totalling 25 fits |
7. 最后通过所有参数的最佳取值来训练模型
1 | other_params = {'learning_rate': 0.1, 'n_estimators': 490, 'max_depth': 5, 'min_child_weight': 1, 'seed': 0, |
3. 模型训练完毕,根据特征 importance 图分析特征重要性
1 | from xgboost import plot_importance |
4. 总结
我们发现,通过调参可以一定程度上提高一些model的分数,但是提升幅度不大,最主要的还是数据清洗,特征选择,pre-pruning 等步骤。
赏
使用支付宝打赏
使用微信打赏
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章